Detailed analysis of Convolutional Neural Network models for object recognition
Introduction
This project implements and compares two Convolutional Neural Network (CNN) models for object recognition using the CIFAR-10 dataset. We analyze a basic model and an improved version with advanced techniques to enhance performance.
Dataset Overview

The CIFAR-10 dataset consists of 60,000 32x32 color images in 10 classes, with 6,000 images per class. The dataset is divided into 50,000 training images and 10,000 test images.
Class Distribution
Each class in the dataset is equally represented, with a balanced distribution of 6,000 images per category. This balanced distribution helps in training models without class imbalance issues.
Model Architectures
Improved CNN Architecture
.png)
Basic Model Architecture
- Two convolutional blocks with convolution and max pooling layers
- Flatten layer for feature vector transformation
- Hidden dense layer with 256 neurons
- Output layer with 10 neurons (one per class)
Improved Model Architecture
- Three convolutional blocks with increasing filter sizes (32, 64, 128)
- Batch normalization after each convolutional layer
- Dropout layers (0.25) after each max pooling
- Larger dense layer (512 neurons) with batch normalization
- Output layer with 10 neurons
Model Comparison
| Metric | Basic Model | Improved Model |
|---|---|---|
| Total Parameters | 545,098 | 1,222,762 |
| Training Accuracy | 0.7773 | 0.7797 |
| Validation Accuracy | 0.6738 | 0.8135 |
| Test Accuracy | N/A | 0.8118 |
| Training Loss | 0.6392 | 0.8063 |
| Validation Loss | 1.0339 | 0.7062 |
Performance Analysis
Improved Model Performance
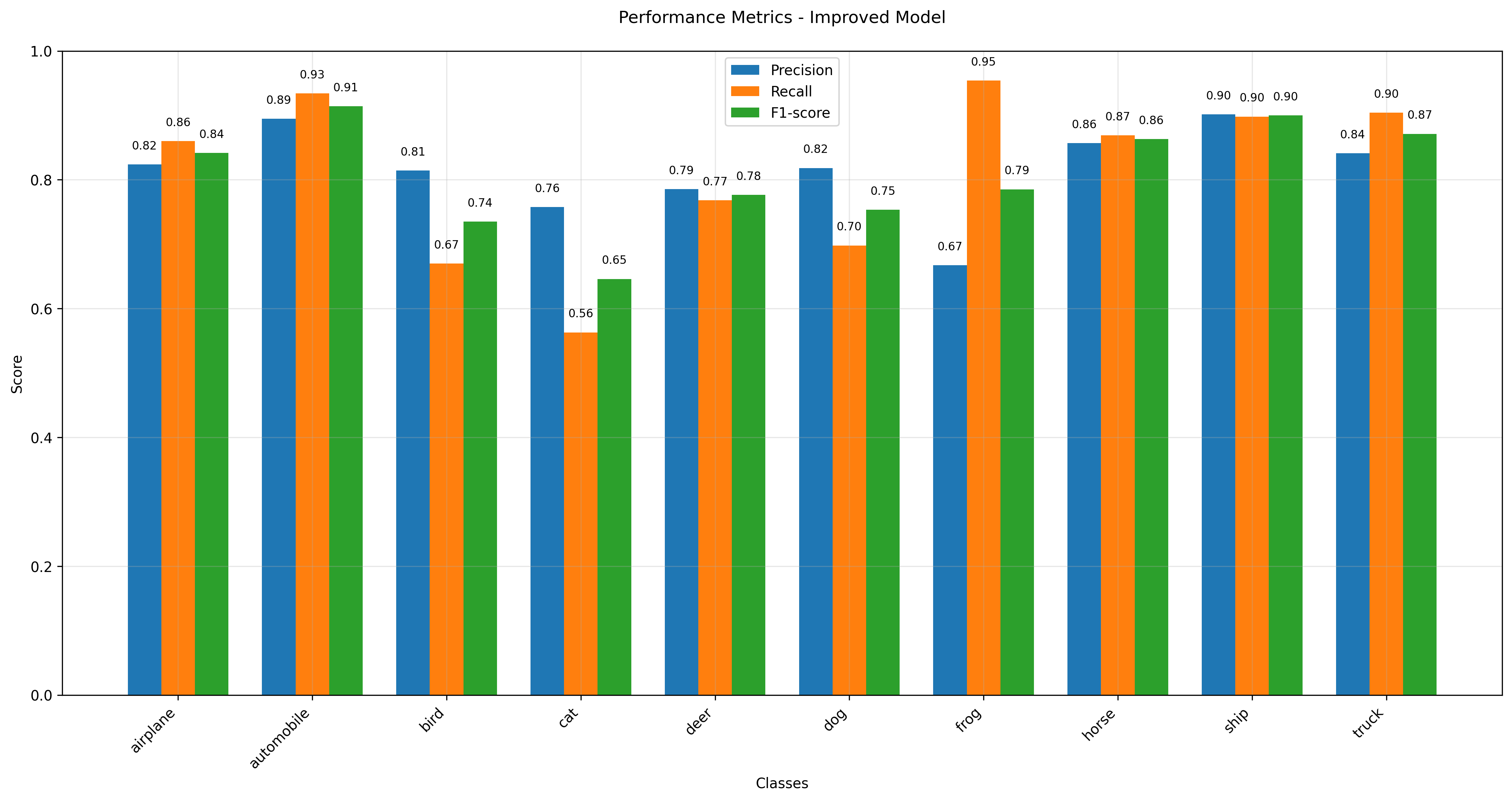
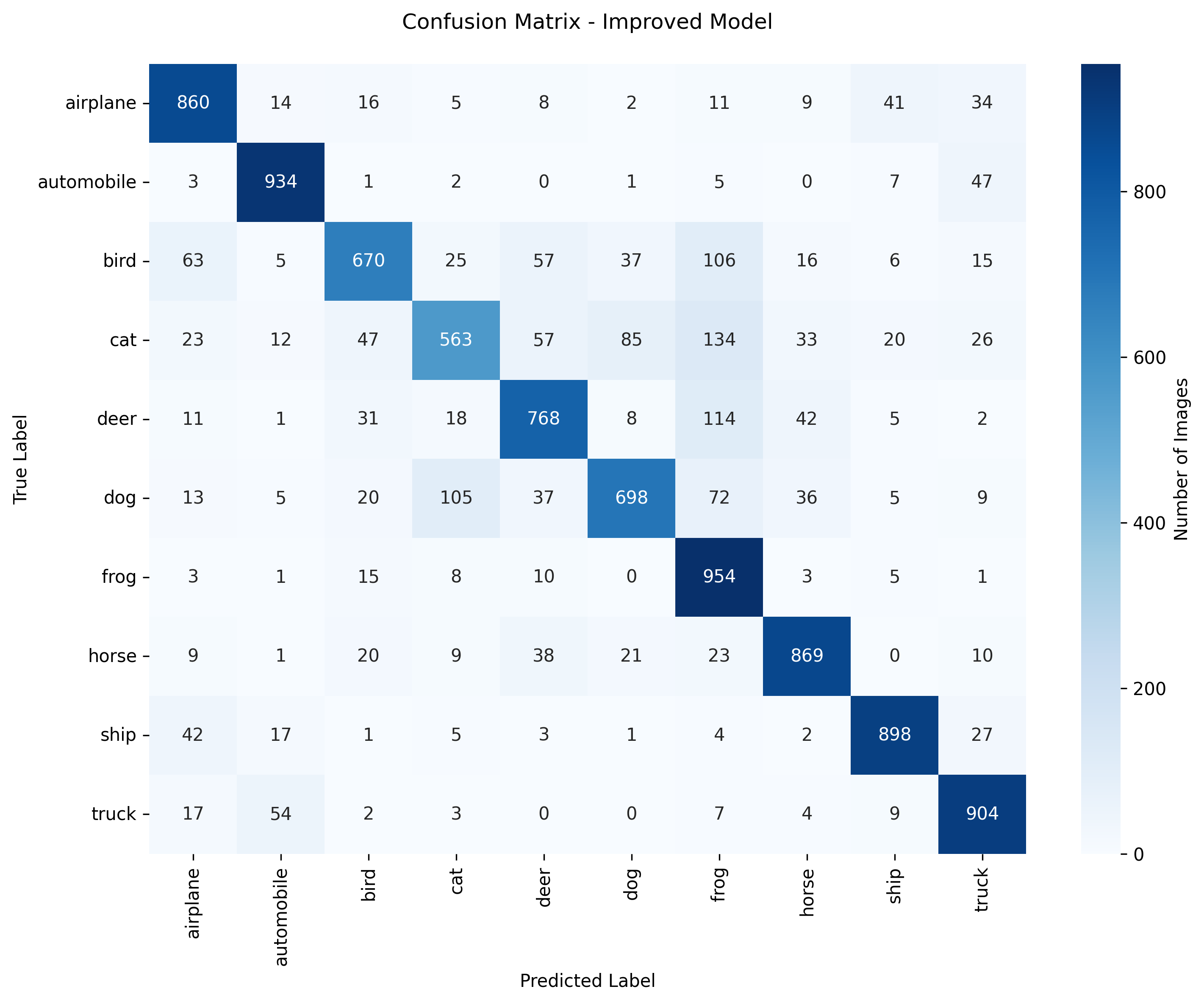
Class Performance Analysis
Best Performing Classes
Automobile: 93%
Ship: 90%
Truck: 90%
Most Challenging Classes
Cat: 56%
Bird: 67%
Dog: 70%
Overall Performance
Mean AUC: 0.9819
Implemented Improvements
Data Augmentation
- Random rotations (±15°), flips, shifts
- Increases data variety without extra labels
- Prevents memorization of training samples
- Boosted validation accuracy + reduced overfitting
Dropout (0.2 → 0.5)
- Randomly disables neurons during training
- Reduces co-adaptation and forces redundancy
- Narrowed gap between training/validation accuracy
- Training accuracy ↓ (expected) → Validation accuracy ↑
Batch Normalization
- Normalizes activations → stable layer input distribution
- Enables faster training with higher learning rates
- Smoother convergence + slight regularizing effect
- Improved deeper layer stability and learnability
L2 Regularization (λ = 0.01)

- Penalizes large weights → favors simpler models
- Encourages generalization by smoothing learned functions
- Slight reduction in training accuracy
- Lower variance in validation performance
Conclusions
Key Findings
- Validation accuracy improved by 14% (from 67.38% to 81.35%)
- Significant reduction in validation loss from 1.0339 to 0.7062
- Best performance in object categories: automobiles (93%), ships (90%), trucks (90%)
- Most challenging categories: cats (56%), birds (67%), dogs (70%)
- Successful mitigation of overfitting through multiple techniques
Key Improvements
- Data augmentation significantly enhanced model generalization
- Batch normalization stabilized training and improved convergence
- Dropout effectively reduced overfitting and improved robustness
- L2 regularization helped in achieving more stable validation performance
- Increased model capacity led to better feature extraction
Future Directions
- Implement advanced architectures (ResNet, DenseNet) for improved performance
- Explore transfer learning from pre-trained models
- Optimize hyperparameters using grid search or Bayesian optimization
- Develop ensemble methods combining multiple model architectures
- Investigate advanced data augmentation techniques for challenging classes